Evaluation Engine (Interpreting Results)
The Evaluation Engine is the final stage of the AutoChunks pipeline. It takes the Synthetic Ground Truth and measures how each candidate strategy performed against it according to your selected Optimization Goal.
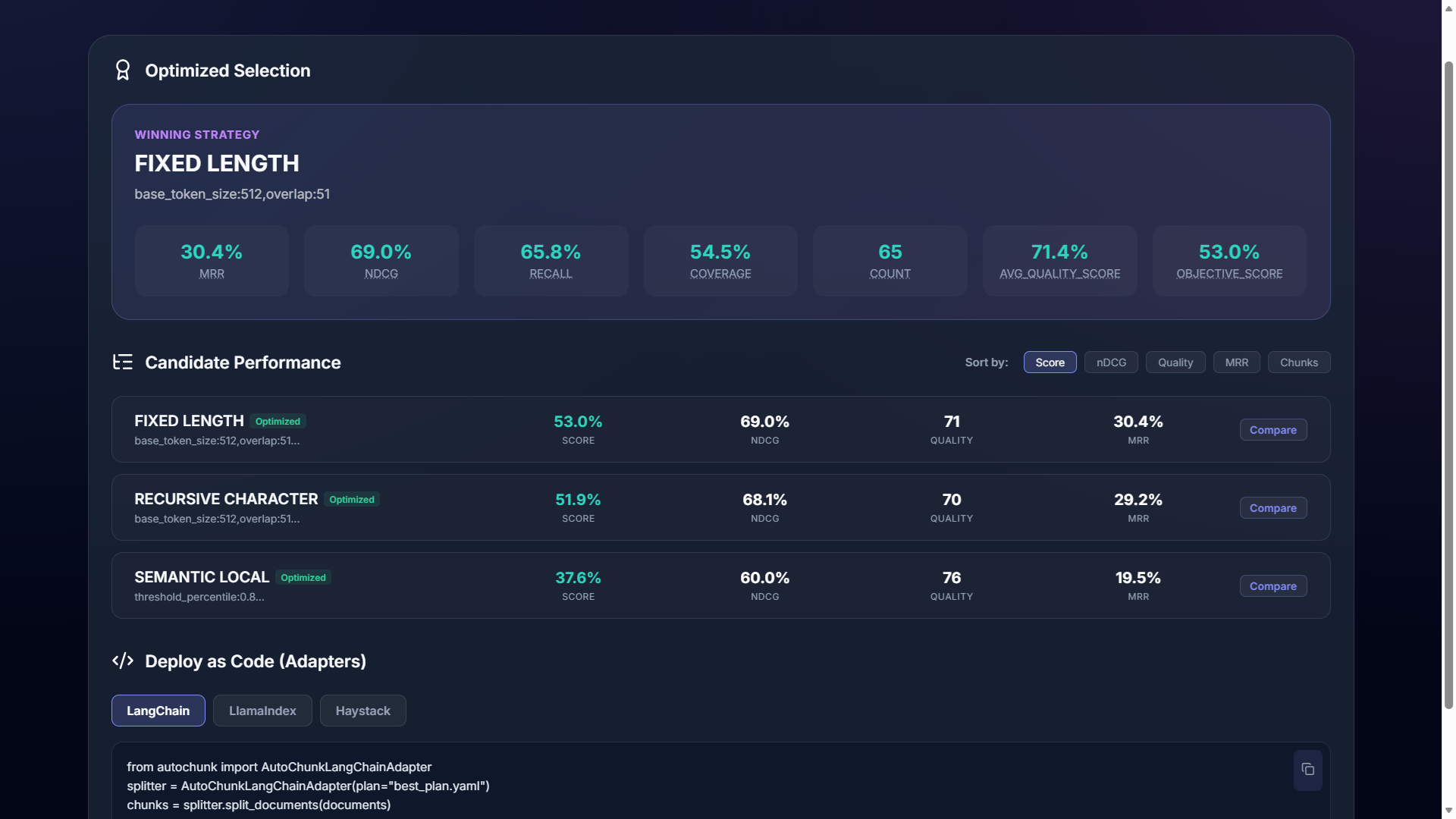
The Scoring Logic
AutoChunks uses a Multi-Objective Composite Score to rank chunking strategies. This score collapses retrieval precision, semantic quality, and infrastructure impact into a single leaderboard ranking.
The Master Formula
For detailed definitions of the variables (\(Q, M, C\)) and how weightings (\(w\)) are applied per goal, please refer to the Optimization Goals documentation.
Metric Overview
1. Retrieval Benchmarks
These metrics measure the "findability" of your data using standard Information Retrieval (IR) benchmarks:
- nDCG (Normalized Discounted Cumulative Gain): Measures ranking position. High nDCG means the exact right answer appeared at the very top.
- MRR (Mean Reciprocal Rank): Measures how deep the user or LLM has to look to find the first relevant chunk.
- Recall / Coverage: Measures if the answer exists at all in the top-k results. Low recall is the primary driver of RAG hallucinations.
2. Infrastructure Impact
We track the total number of chunks generated by each strategy.
- Cost Efficiency: If two strategies have similar quality, the "Winner" will be the one that produces fewer chunks, saving you money on vector storage and LLM inference.
- Logarithmic Penalty: A logarithmic penalty is applied for high chunk counts to prevent "over-fragmentation" of your documents.
Quality Scorer (The "Secret Sauce")
While IR metrics tell you if a chunk can be found, the Quality Scorer tells you if the chunk is actually useful for an LLM to read. AutoChunks evaluates every chunk across five dimensions:
| Dimension | Weight | Purpose |
|---|---|---|
| Semantic Coherence | 25% | Ensures the chunk doesn't mix unrelated topics. |
| Contextual Completeness | 20% | Scans for unresolved pronouns or missing "standalone" context. |
| Information Density | 15% | Penalizes "fluff" and repetition to save tokens. |
| Boundary Integrity | 20% | Rewards cuts made at logical, grammatical sentences. |
| Size Optimization | 20% | Incentivizes chunks that stay within the "Goldilocks" size range. |
Next Steps: After selecting a winning strategy, you can Deploy as Code to apply it to your entire production dataset.